

Point clouds store tremendously detailed information about physical space. This produces large files that can become unwieldy, particularly as projects grow in size. Large projects can include hundreds (or even thousands) of scans, sometimes creating datasets in excess of a terabyte.
Mastering the storage and manipulation of large data sets a must for any surveyor. Cloud technology presents new possibilities for accelerating and simplifying the management of large point cloud datasets. Here, we are going to detail both cloud-based and legacy solutions, along with the additional steps required under any circumstance.
Step 1: The cloud vs on-premise hardware
Storage has become less of an issue than even a few years ago. It’s not hard to find laptops with more than a terabyte of capacity. You can scale up to a 10 terabyte external hard drive for a few hundred pounds. Point cloud processing is not a graphics-heavy operation. Investing in a quality graphics card is only important if you plan on creating 3D models based on the processed point cloud data.
The challenge that point cloud creators face is computing power. The running of registration algorithms is intensive, and although registering a single scan might only take a few minutes, that quickly adds up. In order to effectively process a large dataset, you need a fast processor. But for the largest datasets, this isn’t good enough — you need parallelisation of processing and multi-threaded processes. But, let’s back up for a second.
Option 1: Legacy hardware specifications
Although cloud-based solutions should be your ‘go-to’ in 2020, it’s easier to understand why if we look at legacy standards. These are also important concepts and benchmarks to understand as a redundancy measure, and to make practical end-user device investments. It’s also worth noting that for smaller operations, a quality laptop might be all you need.
First, choose an SSD over an HDD. It will be faster. With the kind of processing and RAM specs needed for heavy-lifting, HDD storage will simply be counterproductive. Remember, the hard drive doesn’t need to be huge — it’s likely that you will want to use external storage for archiving of projects. But a larger internal hard drive will provide you with more flexibility when it comes to using the computer on any given project.
Second, get something with a quality processor and a lot of RAM, point cloud processing is CPU and memory intensive.
RAM: Some point cloud processing software claims minimum system requirements of 4GB of RAM. But this is just the requirement to run the program. 16GB of RAM is your baseline, and ideally invest in 32GB. Power users might want to invest in even more. It’s easier and more affordable to scale up RAM on a desktop. However, it’s unlikely that you will need anything above 128GB under current circumstances.
Processors: You will only be able to unlock the potential of all of that RAM with a good processor. Right now, the Intel Core i9-10980XE is probably the best piece of hardware on the commercial market. High-end Apple products favour the Intel Xeon W.
The question is, can you have an ‘overpowered’ processor? Although you don’t want to dip into ‘budget’ territory, a standard (and far more affordable) Intel Core i7-7820X or AMD Ryzen 7 2700X will work fine. But that is only if you are registering one scan at a time — which brings us back to parallelisation.

Why you need to match your hardware with your software
Some point cloud processing software allows you to register multiple scans simultaneously during segments of the registration procedure, each taking up one thread within a CPU core — a process known as parallelisation. Depending on the software you use, it becomes increasingly difficult to have an ‘overpowered’ CPU.
If you have access to processing software able to parallelisation registration, the fine print around hardware becomes a lot more meaningful. For example, a standard i7 processor has four cores. A high-end i7, however, can pack 8-10 cores (such as an i7-7820X or i7-6950X). The i9-10980XE has 18 cores. Each step up will cost you, but those differences have a huge practical impact on processing speeds.
A side note about Intel: in their latest i7s, Intel discontinued hyperthreading — what AMD calls ‘simultaneous multi-threading (SMT)’. This technology allows each ‘core’ to power two ‘threads’ at once, and each thread can act as an independent processor when it comes to parallelising tasks — doubling the number of effective cores at your disposal. The value of hyperthreading is debatable because ‘hyperthreaded’ actions will run at a slower clock speed than those assigned a dedicated logical core. With that said, the cloud may make all of this a moot point.
Option 2: The cloud
You need quality end-user devices, but the cloud is the future of point cloud processing. There are storage and archive benefits to the cloud. But there are two reasons that we expect the cloud to take over point cloud processing:
- 5G is a game changer when it comes to access.
- Parallelisation can deliver dramatic results in dynamically scalable environments.
Network connectivity: The importance of network connectivity is crucial to a cloud-based solution. You should invest in the best network connections available to you. Ideally, look for speeds in excess of 100mbps, although 50mpbs could be good enough.
The reason that 5G is important is that it delivers broadband-level connectivity to mobile connections. Right now, UK 4G speeds max out at 40mbps. But you are much more likely to experience a range between 8mbps and 10mbps. 5G introduced the possibility of 20Gbps, with 100mbps available everywhere.
If you want to learn more about the workflow changes 5G makes possible, we have written a full guide to cloud readiness for surveyors that you can check out here. It also contains more detail on how to invest in the right network for your system. Top of that list is the fact that some consumer broadband providers supply ‘asynchronous’ connections. These provide different speeds for upload and download, for example, 50mbps download/10mbps upload — often just quoting the faster one. This is fine for general internet use, but it will completely hamstring your point cloud processing operation. Always look into the specifics.
Dynamic parallelisation: Regardless of how you connect to the cloud, the cloud transforms what you can do with information stored there. Primarily, this comes down to the parallelisation of tasks and the near-infinite scalability of cloud-based computing resources, on-demand.
For processing software that can take advantage of multiple threads throughout processing, the cloud offers the option to simultaneously undertake the ‘coarse registration’ of a project of any size. Putting the scans in order (setting scan pairs) will always take longer with more scans. But, in the cloud, you can just keep adding threads.
To effectively approach the cloud this way you need to make sure that your software can undertake multi-thread, simultaneous registration and supports cloud-based processing. You still need a good computer, but your ability to process at speed will hinge more on your bandwidth than CPU. What’s more, this access can be scaled up and down on-demand, meaning you only need to pay for that increased capacity when it’s needed.
We have run a number of tests using our own software. The difference between traditional and cloud-based operations are dramatic. However, the software you use does make a big difference in terms of the practical outcomes you can expect to achieve — something we will get into in the next section.
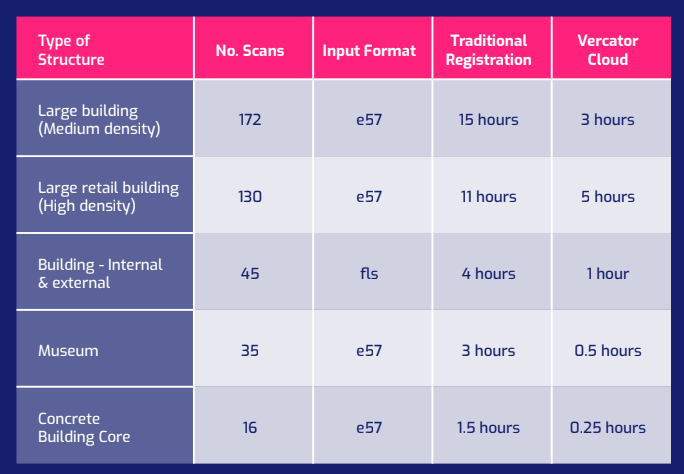
Step 2: Make the right point cloud processing software choices
All of your investments in hardware and quality connections will go to waste if using bad software. Your systems need to work together, not against each other.
First, look for software that allows for the processing of multiple scans simultaneously on multiple threads. Ideally, look for software that can take advantage of multiple threads throughout the entire processing procedure. Second, make sure the solution you pick can operate in the cloud.
The big brand producers of point cloud processing software are Autodesk, Leica, Bentley, Faro and Trimble. These are all quality options. However, all of these software systems come as packages with 3D modelling. If that is not something you are interested in, it will drive up costs. It also means that processing has never been the sole focus of the design teams that built these products.
Processing Speed
Historically, idiosyncrasies between different 3D laser scanners meant that most point cloud processing software was built in-house. This is no longer the case, and the result has been a wide range of new entrants into the market — each often focused on a single aspect of point cloud creation, delivering improvements to either the processing or modelling.
Specialisation allows for faster innovation and often better, yet singular, products. For example, rotational vector analysis allows targetless scans to be registered 40%-80% faster, using traditional hardware. This is accomplished by splitting coarse registration into three stages. Point clouds are compressed into unique ‘vector spheres’, enabling rotational alignment. This allows for rapid 2D point density alignment on the vertical and horizontal axes. But maybe even more importantly than speed, this approach enabled more robust outcomes with less review.
Automation, frontloading and review
Look for software that automates manual processes and frontloads what remains. Cross-checking scans, changing parameters for every pairing, and generally having to be involved throughout the processing period exponentially increases the time costs of handling large datasets.
The ability to build entire scan trees, walk away and deal with verification after the dataset has been processed greatly improves efficiency. It’s also an essential component for practically taking advantage of parallelisation. If your cloud-based system has to continually pause to ask for verification, you won't actually gain much from scaling your computing power.
Look into the review processes available within programs. Ideally, you want options. You can either check the accuracy of data using visualisation features or statistical data. Visualisations give you confidence in the results being correct while statistics tell you ‘how’ correct that data is. It’s important to have both options available if looking to quickly review data and check in detail whether or not the results comply with the job specifications. The quality of such tools to review large quantities of data directly impacts your ability to trust the final output.
Pay particular attention to the interface for scan pairing (building a scan tree). For large projects, this can be a challenging aspect of the processing procedure. A system with a smooth interface that allows for the rapid alignment of scans will significantly reduce the effort and time it takes to handle a large dataset.
Step 4: Learn software tricks to speed up point cloud processing and decrease file sizes
In addition to the critical ability to use multiple threads to process several scan pairs simultaneously, there are three main features that you should look out for. The first is the ability to normalise point distributions throughout a scan field. Laser scanners produce a greater density of point data in the area directly surrounding them. This is an inescapable byproduct of making line-of-site measurements based on incremental angular changes. This excess data, however, is effectively useless. Most programs allow you to set a ‘thinning’ metric that culls all data points within set parameters. Depending on the nature of the project, you will want to set this number somewhere between 5mm and 25mm.
The second feature is ‘decimation’. This is the thinning of point data throughout a scan field regardless of its proximity to the scanner. Unlike normalising, this impacts all data throughout a scene and can easily deteriorate your data files. Decimation should be done carefully. But, if you understand the specific precision requirements of the end result, you can safely reduce file sizes.
The third feature is the maximum distance settings. Laser scanners have an enormous range. If scanning outdoors, or even in a large indoor space, scans can collect point data that is very far away from the scanner. If, in order to get angle coverage, that area is part of another scan anyway, that data is not useful. By setting a maximum distance, you can remove data from your files and decrease the amount of data that has to be processed for each cloud-to-cloud alignment. This is also important to creating a clear end product.
Step 5: Make sure that you can appropriately account for ‘propagation of error’
For datasets with a large number of scans, it’s critical to be able to account for ‘propagation of error’. This is the compounding of inaccuracies and deficiencies in precision as each scan is paired with another. Each pair of scans is effectively built on the next one, all rooting back to a single ‘home’ scan that ‘fixes’ the entire composite point cloud. The more links between any given scan and its ‘home’ scan, the greater propagation error it will suffer.
For example, imagine aligning a dataset in which each scan had an error of +/- 2mm. Your home scan will have an error +/- 2mm. But, each step you take away from that scan will suffer an ever increasing level of error equal to the sum of the errors squared. Therefore, although each adjacent scan will have an inherent baseline error of +/- 2mm, it's error within the composite scan will be +/-16mm. This will only increase as you move further away. [(n1*2)2 + (n2*2)2 … = total error (where ‘n’ is the error rate for each scan)]
This is why it’s important, even in small datasets, to place the home scan in the middle of the scan tree. For large scan sets, you need to subdivide the entire scan file with multiple home scans dispersed at intervals that will keep the whole dataset within the maximum tolerable error rate.
To do this, you need software that can take two or more point clouds that have gone through coarse registration and combine them prior to doing a ‘global’ fine registration. However, the bedrock of this capability is rooted in the surveying techniques used in the field. For large projects, surveyors need to build a rigorous network of targets using a total station that can act as a control frame for the global placement of scans. This does not mean that each scan pair has to be aligned using targeted registration. Surveyors simply need to think about the end requirements of the project and build a site grid that will allow for cloud-to-cloud registration in containable chunks that will not be overly corrupted by propagation of error.
Large Datasets Require Planning
Large datasets are a challenge, but they can be overcome with planning. That starts with thinking about the level of precision required in the finished point cloud, along with the number of scans your survey will produce. It’s possible that to meet the job specifications, you will have to construct a site grid using a total station to account for the propagation of error. Next, make sure that your hardware is up to the task and that you pick software that compliments your strategy.
The cloud is the future of large-scale point cloud processing. The dynamic scalability offered by the cloud provides such powerful results for parallelising tasks that it’s hard to think of a more compatible solution. But the transition has only begun. That means it’s important for you to take your software choices seriously. Not all registration software will be cloud compatible, and not all software will deliver robust enough outcomes that effective use of the cloud’s scalability is possible.
With that said, if speed is not an issue for you, it’s important to remember that large datasets aren’t fundamentally different than smaller ones. Just plan ahead and give yourself enough time to process and handle the large files. A high-quality laptop will be good enough to slog through almost anything you throw at it — it just might take a while.
Lastly, make sure that you have access to enough storage to keep the final datasets. However, given the state of modern computing, that is realistically the least of your worries. For long-term storage, the cloud, again, is a good option.

Tags: point clouds
